


鱼羊 发自 凹非寺
新一年的基础模型竞逐,没想到是阿里千问率先出手了!
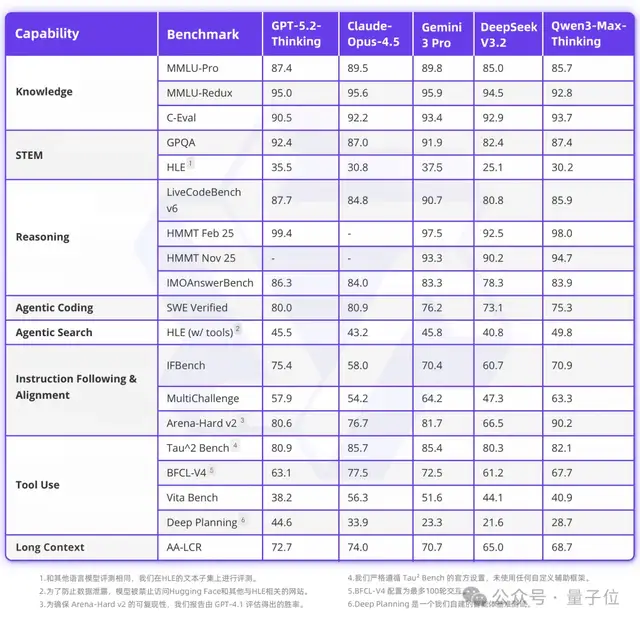
就在刚刚,Qwen3-Max-Thinking正式版突然发布,当即刷新全球SOTA:
在涵盖科学知识、数学推理、代码编程的19项权威基准测试中,赶上甚至超越GPT-5.2-Thinking、Claude-Opus-4.5和Gemini 3 Pro等TOP闭源模型。
p.s. 此前这一超大杯推理模型的“早期预览版”,已经在AIME 25和HMMT 25(哈佛-MIT数学竞赛)中达到100%的准确率。
核心技术方面,通过引入自适应工具调用和测试时扩展两项技术创新,Qwen3-Max-Thinking的推理性能和调用工具的原生Agent能力都有显著提升。
千问APP PC端和网页端已经第一时间上新这一Qwen系列最强模型,现在即可免费体验。API(qwen3-max-2026-01-23)也已开放。
话不多说,Qwen3超大杯推理版到底有多强,我们直接来看效果。
代码能力
现场写一个小游戏,对大模型们来说早已不是难事,什么贪食蛇、flappy bird基本都能轻松搞定。
如果再加上一点难度,让Qwen3-Max-Thinking在网页小游戏里加上手势识别呢?
创建一个基于浏览器的气球射击游戏,使用天空背景,并通过摄像头跟踪用户的手部动作来控制屏幕上的指针。
还真能work!并且在prompt的指导下,细节也都到位:
瞄准动作下,屏幕左上方会显示“瞄准中”的状态;双指捏合触发射击时,能瞬间转换“射击!”提示;如果手出框了,还会出现红色高亮提醒。
完整prompt如下:
再来一手经典难度题:鹈鹕骑自行车。
An animated SVG of a pelican riding a bicycle.
emmm…谈不上完美,但鉴于给出的提示词比较简略,至少确实是那么个意思了(doge)。
工具调用
此次更新,官方重点强调了两方面的能力提升:推理能力和自主调用工具的原生Agent能力。
刚好最近在关注内存涨价这事儿,不妨让Qwen3-Max-Thinking直接帮我们分析一波,写份研报。
提示词:
最近内存价格疯涨,帮我分析下哪些股票受到了影响,画出相关股价走势
从侧边栏显示的思考细节可以看到,Qwen3-Max-Thinking先是自主上网收集好了资料,然后调用代码解释器做起了数据分析和绘图,就像人类一样是边用工具边思考的。
不到1分钟时间,一份囊括涨价原因、受益/受损产业分析、下一阶段存储芯片产业走势的完整报告,就新鲜出炉了。
在模型上线的同时,阿里千问团队也通过官方技术博客,透露了Qwen3-Max-Thinking的不少技术细节。
技术博客提到,Qwen3-Max-Thinking在事实知识、复杂推理、指令遵循、人类偏好对齐以及智能体能力等评估维度上都实现了显著提升。
背后有两项核心创新:
来看具体细节。
自适应工具调用
与早期需要用户手动选择工具的方法不同,通过引入自适应工具调用,Qwen3-Max-Thinking能在对话中自主选择并调用其内置的搜索、记忆和代码解释器功能。
比如,搜索《醉翁亭记》全文,并调用代码解释器把所有的“也”替换成“喵”。
最终的完成效果如下:
在此背后,阿里千问团队专门设计了一套训练流程:
在完成初步的工具使用微调后,模型在多样化任务上使用基于规则和模型的反馈来做进一步训练。
实验表明,搜索和记忆工具能有效缓解幻觉,提供实时信息访问,并支持更个性化的回复。代码解释器允许用户执行代码片段,并应用计算推理来解决复杂问题。
测试时扩展技术
测试时扩展是指在推理阶段分配额外计算资源,以提升模型性能的技术。
阿里千问团队提出了一种经验积累式、多轮迭代的测试时扩展策略。
不同于简单增加并行推理路径数量N(这往往会导致冗余推理),研究团队限制N并将节省的计算资源用于由“经验提取”机制引导的迭代式自我反思。
这样做的好处在于,模型不会推理着推理着又绕回到已经得出的结论上去,疯狂废话浪费token,而是会专注于未解决的不确定性。
更关键的是,相比于直接引用原始推理轨迹,该机制实现了更高的上下文利用效率,在相同上下文窗口内能更充分地融合历史信息。
实验证明,在大致相同的token消耗下,该方法优于标准的并行采样与聚合方法,推理性能和推理效率大幅提升。
比如,在启用工具的“人类最后的测试”HLE中,Qwen3-Max-Thinking得分58.3,超过GPT-5.2-Thinking的45.5,以及Gemini 3 Pro的45.8,刷新SOTA。
在IMO难度级别的数学能力测试基准IMO-AnswerBench上,Qwen3-Max-Thinking也以91.5的成绩拿下全场最高分。
意料之中,2026年的第一个重量级模型更新,再次来自中国。
而有些意料之外但也在情理之中的是,这一次率先出手的,是阿里千问。
根据MIT-Hugging Face数据,在全球22亿次模型下载行为之中,中国开源AI模型的采用份额已经跃升至17.1%,超过了美国的15.8%。
在过去一年内新发布的模型中,中国模型的下载量稳居第一。
在其中,从迭代频率、下载量和社区影响力来看,千问系列拔得头筹。
Hugging Face的最新数据显示,阿里千问系列衍生模型数量突破20万个,成为全球首个达成此目标的开源大模型。同时,千问系列模型下载量突破10亿次,平均每天被下载110万次,完全超越Llama,实际上已经成为全球AI开源界的新标杆。
值得关注的是,在飞快壮大自身开源、顶级模型影响力的同时,阿里也已在实践中揭示了2026年模型厂商的新着力点——
将顶尖模型能力和应用生态体系做更深入的结合。
日前,千问APP已全面接入淘宝、支付宝、淘宝闪购、飞猪、高德等阿里生态业务。
可以预见的是,2026基础模型还将持续增强,并且更深入地与各个垂直领域、与实际生活相结合,在落地实践中展现更多应用的可能。
第一炮已经打响,期待中国开源延续2025年的势头,持续给世界带来新惊喜~
官网地址:https://chat.qwen.ai/
版权声明:
本博客部分内容为转载文章,旨在分享有价值的信息,版权归原作者所有。
转载仅为个人学习与交流目的,不对文章观点负责,亦不用于任何商业用途。
如涉及版权问题,请联系本人删除。